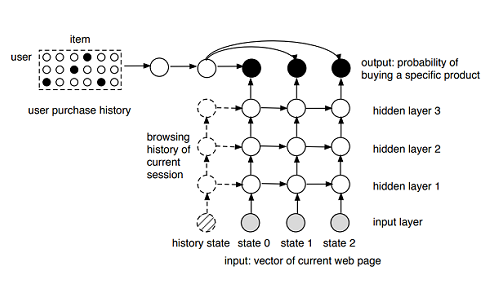
ResNet: Deep Residual Learning for Image Recognition (CVPR 2016 Paper)
ResNet is proposed in the 2015 paper Deep Residual Learning for Image Recognition to solve the problem of the increasing difficulty to optimize parameters in deeper neural networks. By introducing identity shortcut connections in the network architecture, the network depth can easily reach 152 layers and still remain easy to solve. As a comparison, VGG, the previous state-of-the-art network proposed in 2014, has only 16 layers. It is widely recognized that the increased depths in deep convolutional neural networks (CNNs) are extremely helpful in computer vision tasks. From the input to the output, each layer of the network is essentially performing low to high-level feature extraction. By adding more layers, more fine-grained levels of features can be extracted and processed. As a result, ResNet won many computer vision competitions in 2015 and has been proven to be extremely powerful.
As the number of layers in a CNN increases, the model complexity increases. Theoretically, a more complex model should be able to fit the training data better and achieve a lower training error. However, a deeper model usually has difficulty converging. The convergence issue comes from vanishing/exploding gradients, which can be largely addressed by normalizing initialization and inserting Batch Norm layers between regular network layers. However, even with normalization, experiments still show that the training error usually increases with the number of layers, indicating there is an increased difficulty in parameter optimization.
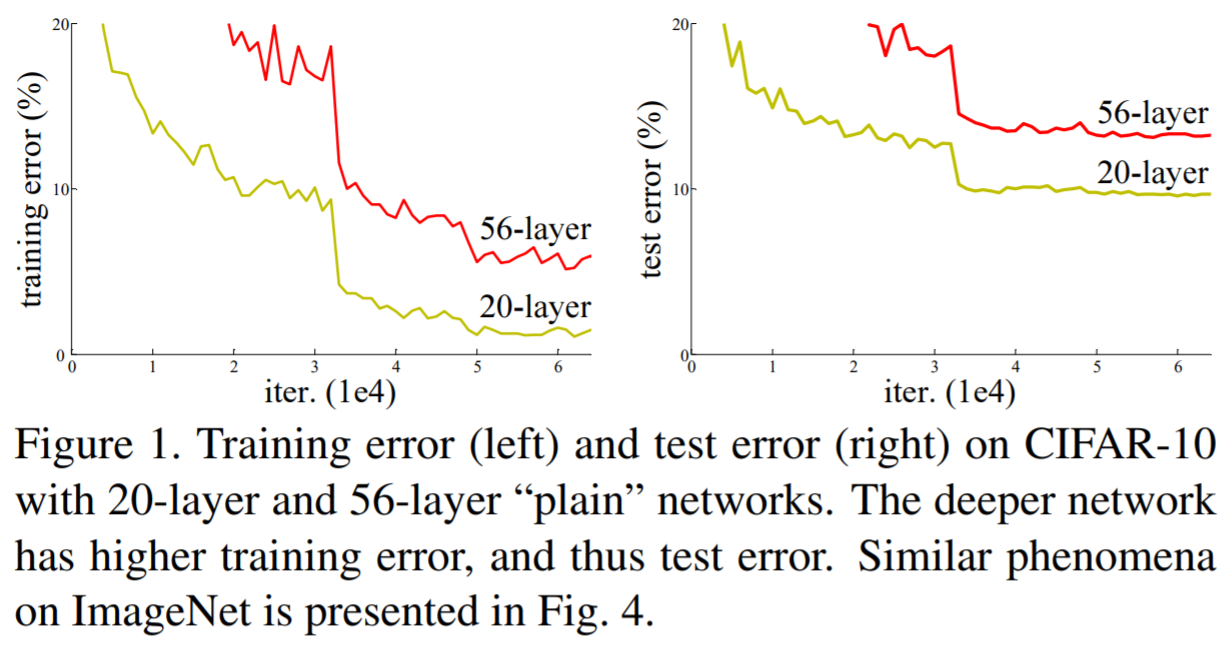
ResNet attempts to remedy this problem by introducing shortcuts that skip one or more layers. A typical building block of ResNet looks like this:
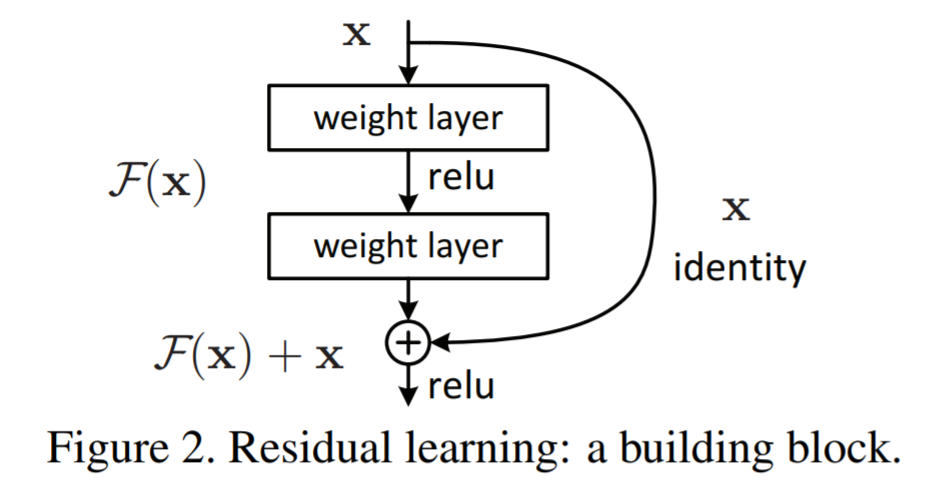
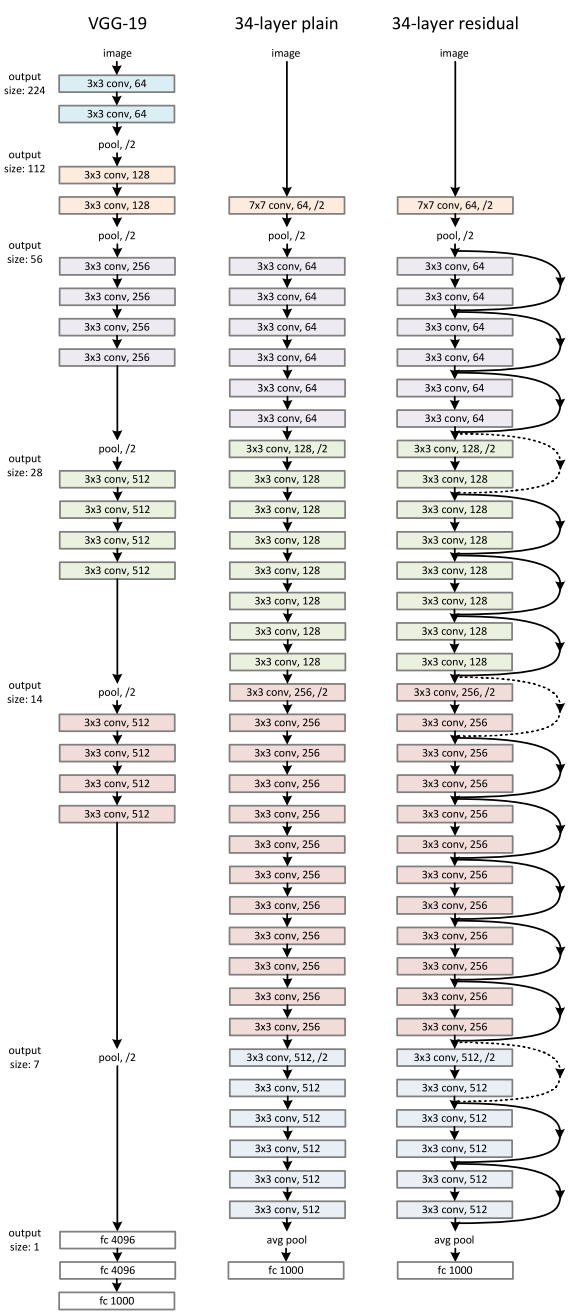
The identity shortcut introduces the term \(x\) to the output and makes the output function take the form of \(F(x) + x\). As a result, the output neuron only needs to learn the residual that is \(F(x) = H(x) - x\). The authors performed extensive experiments to compare the same network with and without the shortcuts, and also observe the behavior when the depth of the network reaches 1,000 layers. The shortcuts prove to be extremely helpful in the training process, and it significantly reduces the resulting training error. Below shows a 34-layer ResNet architecture, compared with a plain version (without shortcuts) and the VGG network.
Another building block architecture that skips more levels and reduces the number of parameters is shown below. It is called a bottleneck building block because of the temporary feature dimension reduction done by the 1x1 convolution layers.
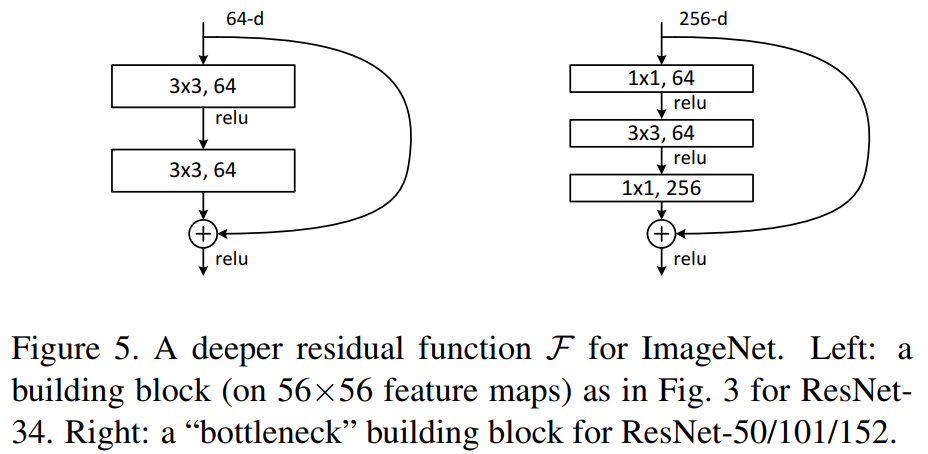
This allows a fast training process for a network as deep as 1,000 layers.