F-RankClass
F-RankClass stands for Feature-Enhanced RankClass. It is an algorithm for joint text and image classification. The F-RankClass project began as a class project for CS512: Data Mining Principles by Prof. Jiawei Han, which I took at UIUC in Spring 2013. It is an extension of RankClass, a ranking-based classification algorithm proposed by Prof. Han’s research group and published at KDD in 2011. Prof. Han was impressed with our class project, and encouraged us to polish it and submit it to International Conference on Data Mining (ICDM), and it got accepted and was published in December 2013.
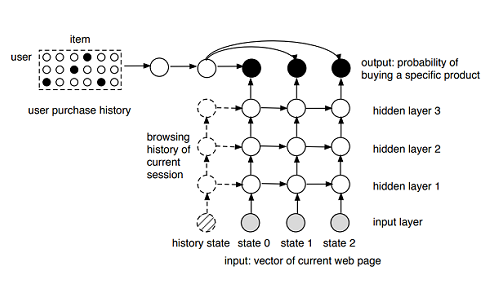
RankClass and F-RankClass are both semi-supervised Heterogeneous Information Network (HIN) mining algorithms. A heterogeneous information network is composed of multiple types of nodes that represent different types of objects, and multiple types of edges that represent different types of relationships between objects. RankClass performs simultaneous, mutually enhancing ranking and classification on HINs based on the intuition that highly-ranked objects in a class are more representative of the class, and also that class membership information is relevant in ranking objects in the dataset. RankClass experimented on data extracted from dblp, a computer science bibliographic information aggregation website. The nodes in the HIN are authors, papers, venues, etc., and the edges represent relationships such as an author writes a paper, a paper is presented at a venue, etc. The goal is to classify and rank the prominent authors and papers in different research areas. By giving class labels (research topics) to a small number of nodes, the algorithm propagates the class and ranking information throughout the HIN, and in the end obtains class and ranking scores for each node.
In the class project, we experimented on the 2008/9 Wikipedia for Schools, a selection of 5,500 Wikipedia articles with 34,000 images. To us, Wikipedia is an exciting dataset to work on because it is a real-world dataset and contains user-generated data. The goal to classify the articles into different categories, or topics. A multimodal document contains multiple modalities: text, images, videos, etc. As a Wikipedia article contains both text and images, it is a multimodal document.
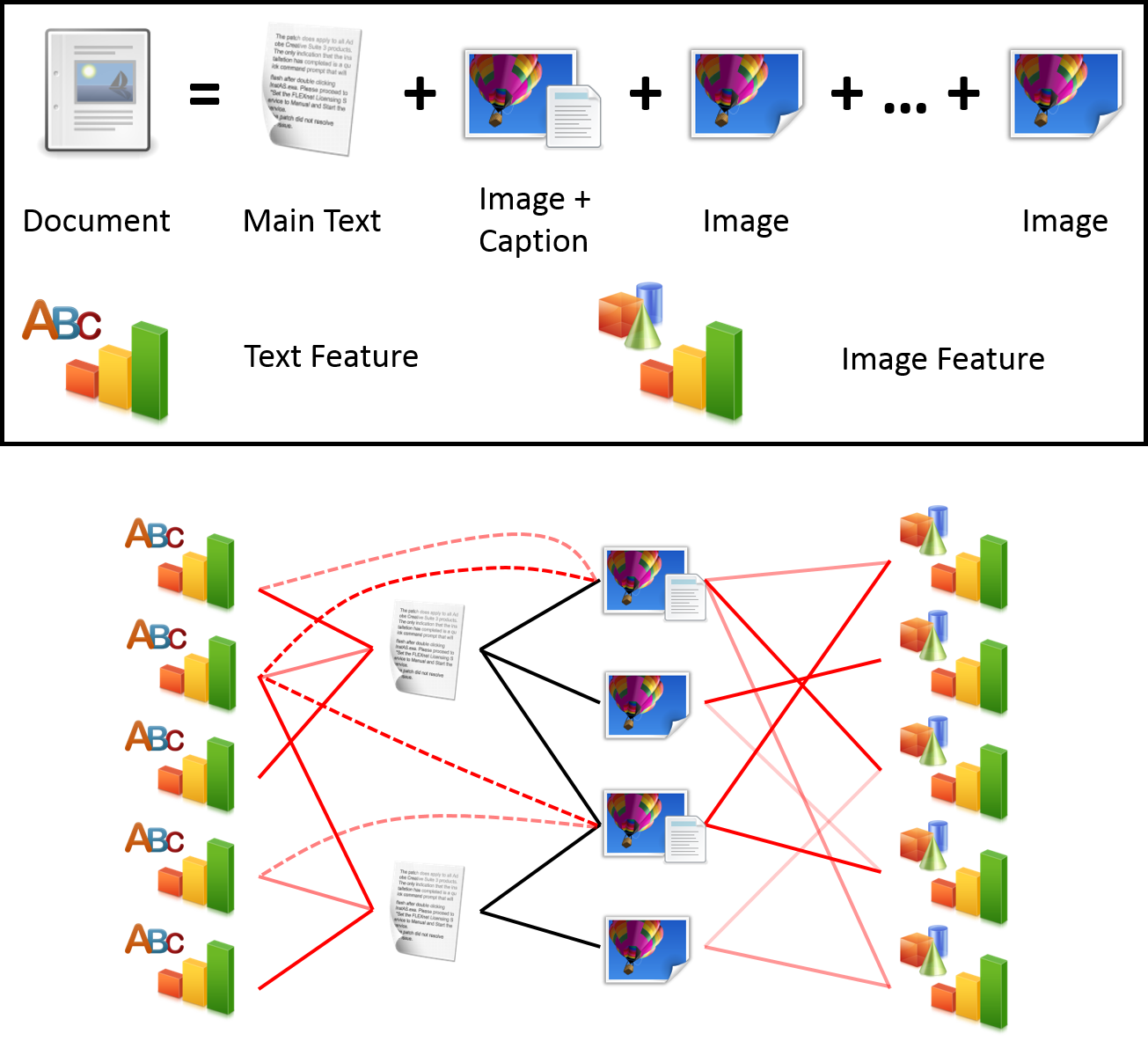
To build an HIN for these Wikipedia articles, we treated each document and each image as a node. An edge forms between a document node and an image node when the image appears in the article. We scraped the Wikipedia pages in the HTML format and built the graph representing it. However, as documents rarely share the same image, the resulting HIN contains many disjoint component and is not suitable for running RankClass.
In order to introduce more connections, we proposed the creation of feature nodes, linking each document with the text features extracted from it, with the edge weights being the feature values. Similarly, each image is connected to image feature nodes, and each image caption is connected to text feature nodes.
By including the feature nodes, F-RankClass naturally provides a unified framework for both binary and multiclass classification of multimodal and unimodal datasets. Another merit of F-RankClass is that it does not require features extracted from multimodal data to have a fixed dimension as only extra links between nodes representing features and data objects are added.
We further split the Wikipedia dataset into 3 sub-datasets:
- Art, IT
- History, Science
- Business, Language/Literature, Math, Religion
We performed binary classification on Datasets 1 and 2, and performed multiclass classification on Dataset 3.
The first experiment is a unimodal, text-only classification task.
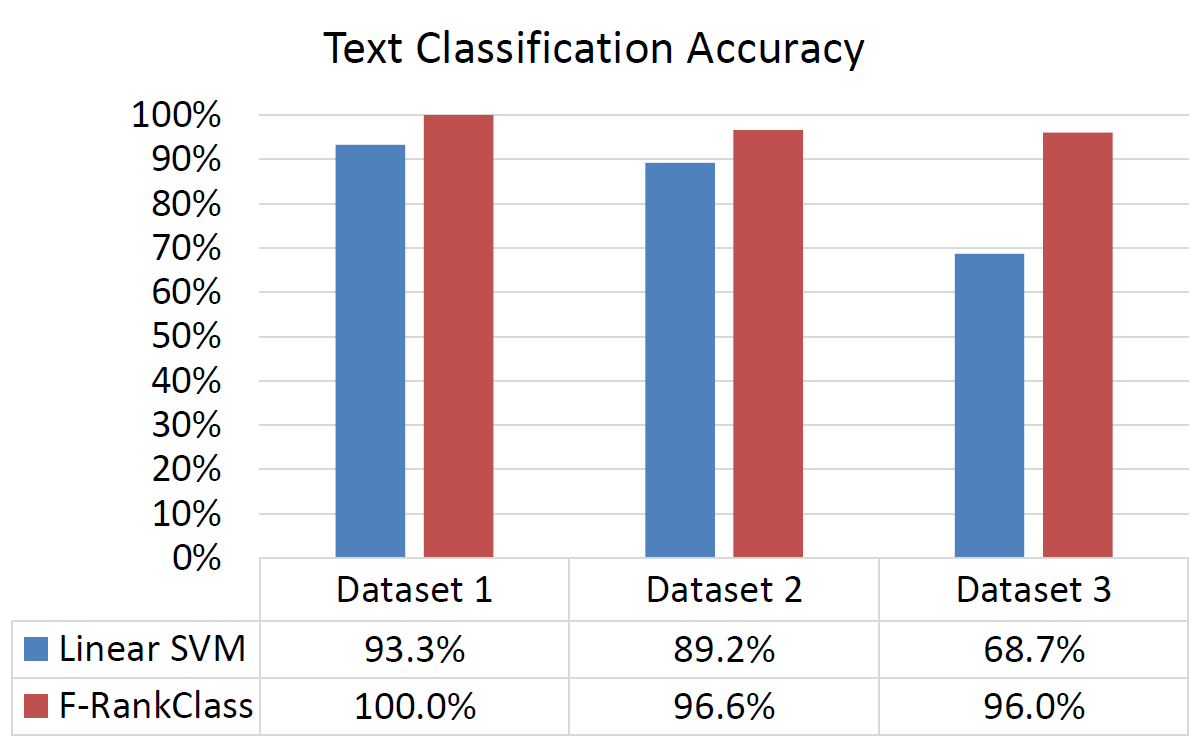
Next, we performed joint text-image classification.
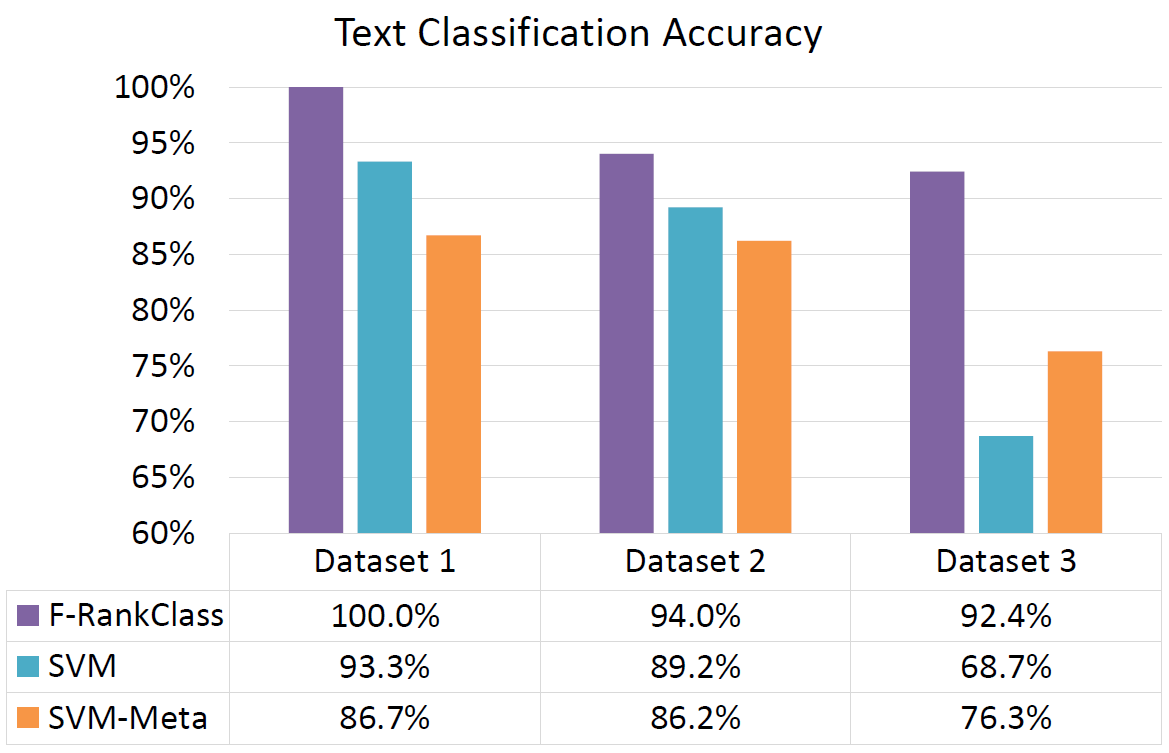

More experiments on image-only classification, hyperparameter tuning, and other details can be found in the paper.