The GANder Project
After building the Goose Dataset and using it to run object detection experiments, I thought of another application with the dataset: generating artificial geese with Generative Adversarial Networks (GANs).
GAN
The idea behind GAN is to have a generator that generates artificial images and a discriminator that distinguishes fake/artificial images from real images in the training set. In each learning iteration, the generator learns to generate better images that cheats the discriminator, and the discriminator learns better criteria to detect fake images.
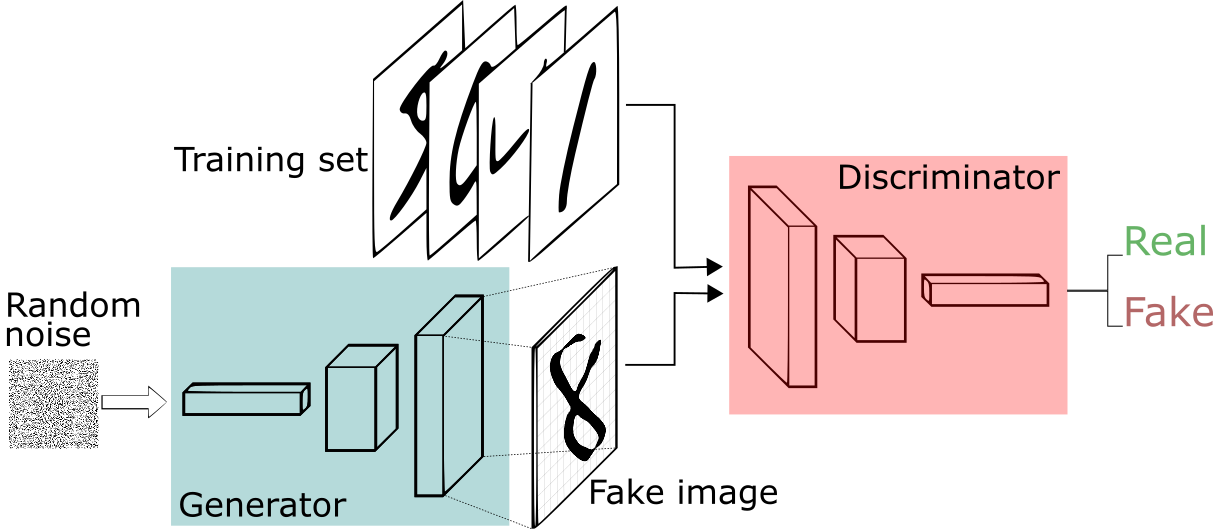
Many GAN implementations, including the original paper, tested on the MNIST dataset. The images in MNIST are grayscale and are of size 28 x 28. To make the Goose Dataset more similar to this and hopefully achieve similarly high-quality results, I cropped the goose heads from the images, turned them grayscale, and resized them to 50 x 28.

I based my experiments on eriklindernoren/Keras-GAN, a Keras implementation of GAN. The vanilla GAN has a simple architecture and is very fast to train on a personal computer without a GPU. It took me less than 2 hours to train for 60,000 epochs. The loss and accuracy of the discriminator and the loss of the generator are displayed for each epoch, and a collection of 25 generated images is saved for every 200 epochs.
From the generated images, we can see the progress of the learning process of GAN.








Next, I increased the number of channels to 3 to include RGB colors instead of using grayscale. The results are not good. Even after 60,000 epochs, only noises were generated.

I tried resizing the images to be slightly smaller, decreasing the width from 50 pixels to 42. Then, goose faces were learned, although a bit disproportioned due to resizing. A mostly green and blue background is also learned, likely due to the fact that most of the backgrounds in the dataset are either grass or water.
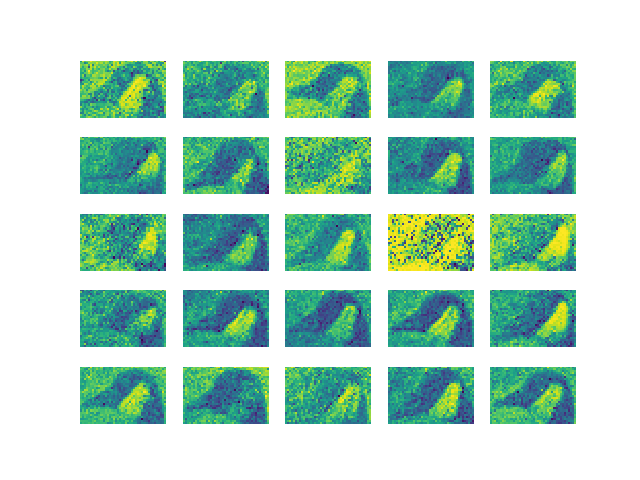
Analyzing the above results, I can see a few issues:
- Some groups of images are repeated and are almost visually identical. This is called mode collapse. Here is a short article explaining mode collapse.
- Noises. The quality of the final results resemble some of the earliest photos from the 19th century (especially the grayscale ones). There are a lot of noises, and the edges are not very well-defined. Moreover, some images are still almost pure noises even after 60,000 epochs of training.

After some survey, I found that these are common issues with GAN, and people have been proposing new approaches to address them.
WGAN
Wasserstein GAN (WGAN) is one improvement work. In the WGAN paper, the authors put emphasis on WGAN’s ability to overcome mode collapse. They showed side-by-side comparison with GAN in the experimental results. In one example, WGAN is also able to learn where GAN failed to learn anything but noises. These look like the improvement I need for this project as well. These improvements are achieved by replacing the Jensen–Shannon (J-S) divergence that the original GAN discriminator optimizes for with the Wasserstein distance or Earth Mover (EM) distance. The original GAN discriminator treats a very poor fake image and a slightly improved fake image all the same, so it does not reward small, incremental improvement in the quality of the generator. On the contrary, the Wasserstein distance is able to distinguish incremental improvement and encourages the generator to make such improvement.

I based my experiments on the same repo, eriklindernoren/Keras-GAN. I slightly adapted the neural network architecture to accommodate for rectangular rather than square images, and then ran the experiments with grayscale cropped images. WGAN is more computationally expensive than the vanilla GAN, and it took me 8 hours to run 30,000 epochs on a personal computer with a GTX 980 GPU. Here are the results.

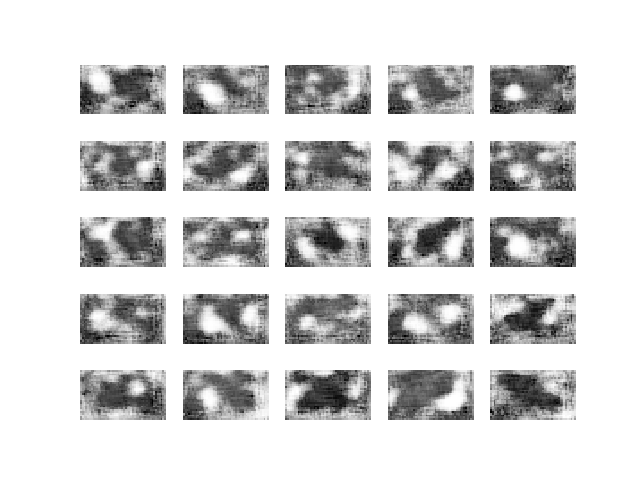
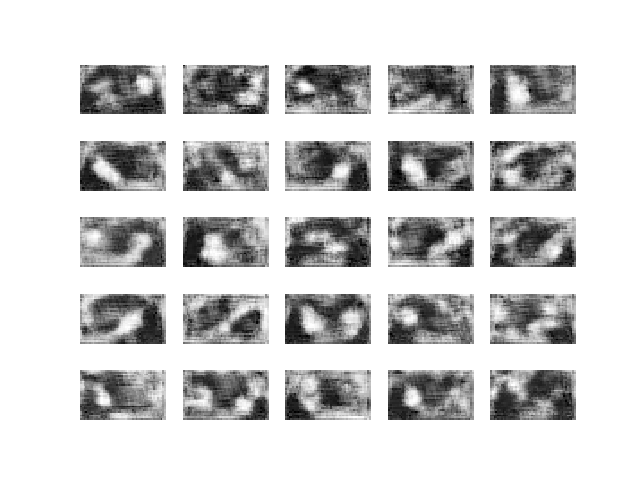
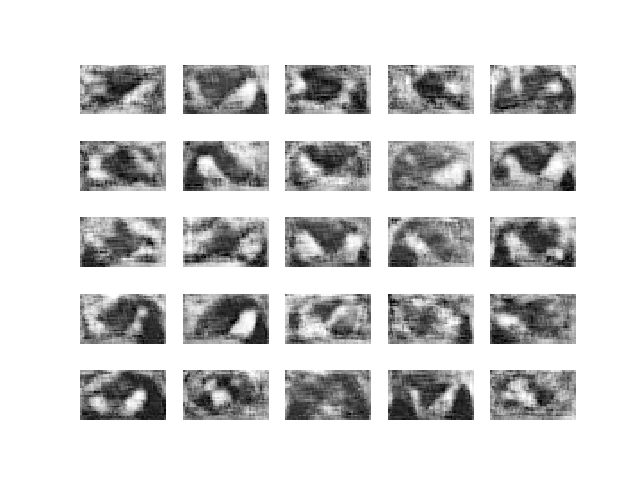
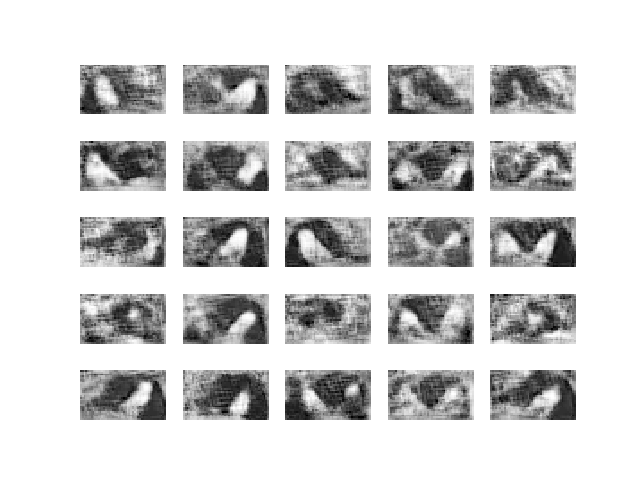
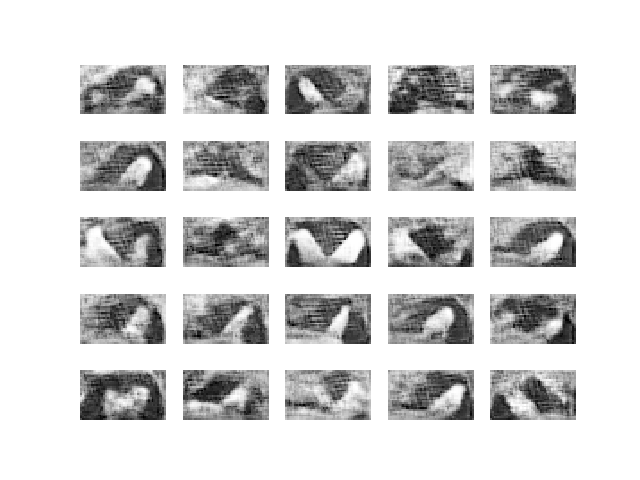
I continued to let it run for a couple of days and got to Epoch 200,000.

VAE-GAN
Another adaptation of GAN is Variational Autoencoder (VAE) GAN. The main idea behind VAE-GAN is to recognize that the generator part of GAN is equivalent to the decoder part of an autoencoder. A VAE encodes the original data into two components, mean and variance. This helps learning the similarities in data and produces higher-quality images.
I based my experiments on tatsy/keras-generative, another Keras implementation of GAN. This time, I did not change the network architecture. Instead, I padded my rectangular images with black strips on the top and the bottom. The repo only provided implementation of conditional VAE-GAN, so I added the same label to all the input data. These experiments took the longest to run, taking a few days for just over 1,000 epochs on a personal computer with a GTX 980 GPU. Here are the results.





Future Work Ideas
- GAN is sensitive to hyperparameters. The hyperparameters and neural network architecture can be further explored to find the optimal setting to generate goose faces. Having access to more computation power would also help.
- Use Conditional GAN to control goose face features such as the presence of eyebrows, the presence of a white bar on the forehead (a good identifier of the Branta canadensis maxima subspecies), the presence of white circles around eyes, open or closed eyes, open or closed mouths, etc.
- Use Disentangled Represenation (DR)-GAN to generate goose faces from different angles.