Real-Time Object Detection
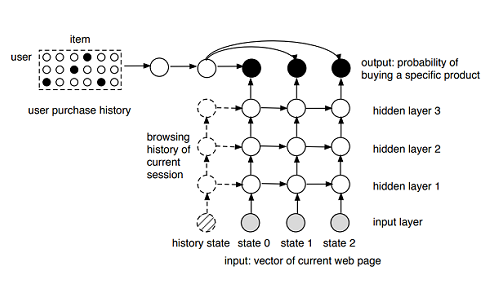
This is a real-time object detection system based on the You-Look-Only-Once (YOLO) deep learning model. I did a similar project at the AI Bootcamp for Machine Learning Engineers hosted by deeplearning.ai, doing literature and resource survey, preparing the dataset, training the model, and deploying the model. After the bootcamp, I decided to dig deeper in various aspects of the system with my own dataset.
Model Training
I based this project on the thtrieu/darkflow implementation of the YOLOv2 object detection algorithm. The output of the algorithm are bounding boxes of each detected object and their associated confidence scores. The input are images or videos.
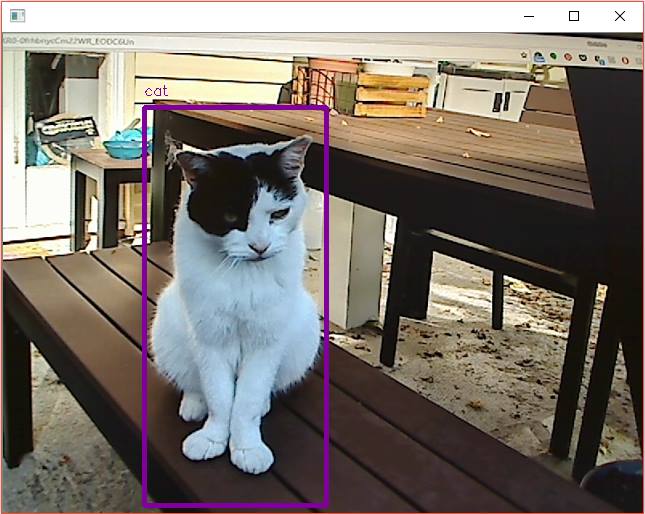
Both darkflow and YOLOv2 provide pretrained weights for several neural network architectures. By loading the pretrained weights, I was already able to detect things. For example, I used the tiny-yolo-voc architecture (a lightweight, 20-class object detection network) and it was able to detect a cat in an image:
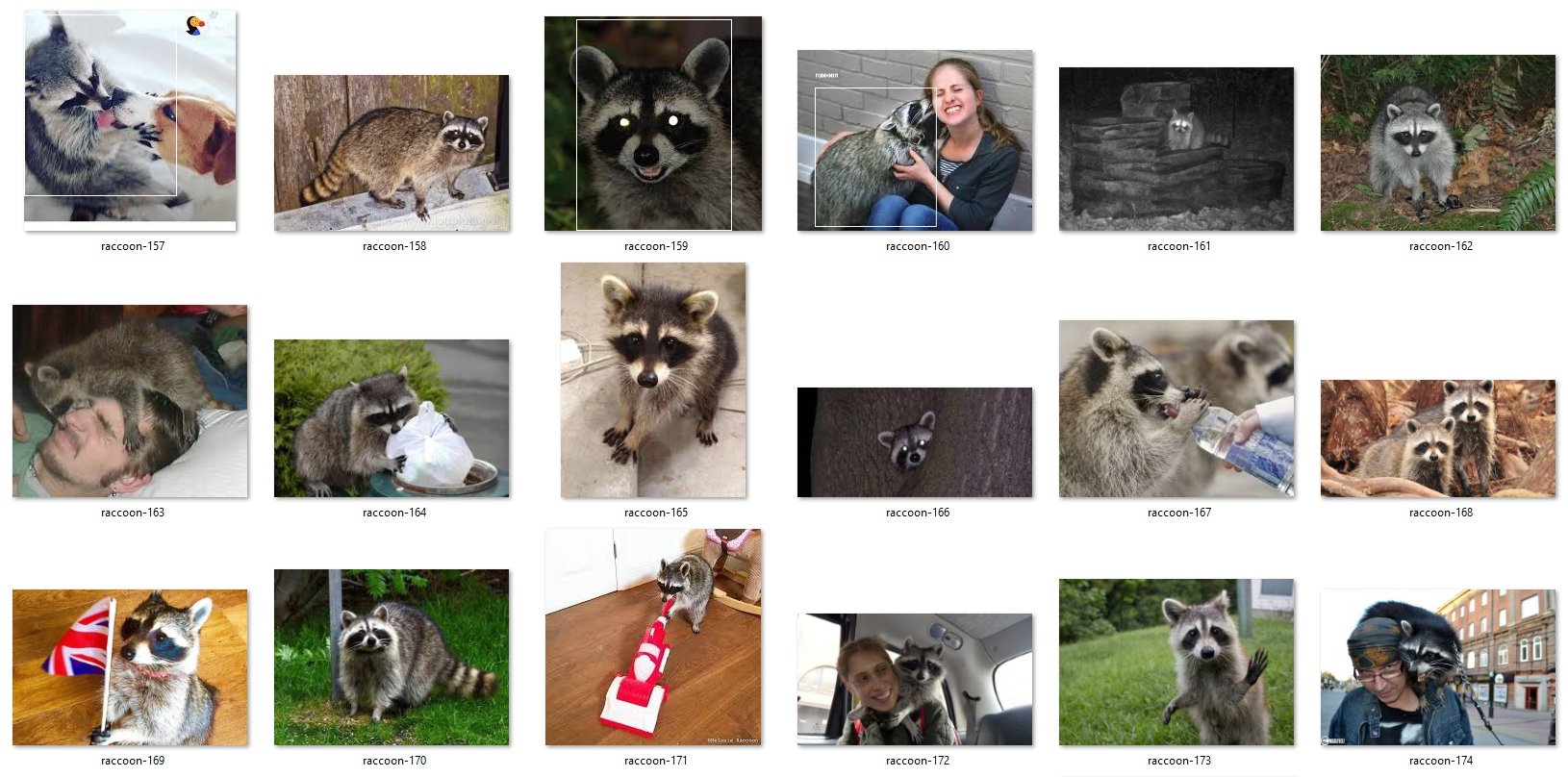
Then, I wanted to apply transfer learning, fine-tuning the weights by providing training data from a different source. I first tried the Raccoon Dataset. Raccoons are not one of the 20 object classes that tiny-yolo-voc was trained on, so training the network to recognize raccoons would be a good transfer learning application. However, it turned out that with only 200 images and great variations in raccoon poses, lighting conditions, background complexity, etc., YOLO is not doing a great job after fine-tuning. It was able to detect most raccoons in the training set, but failed to detect any raccoon in the testing set, showing significant overfitting.
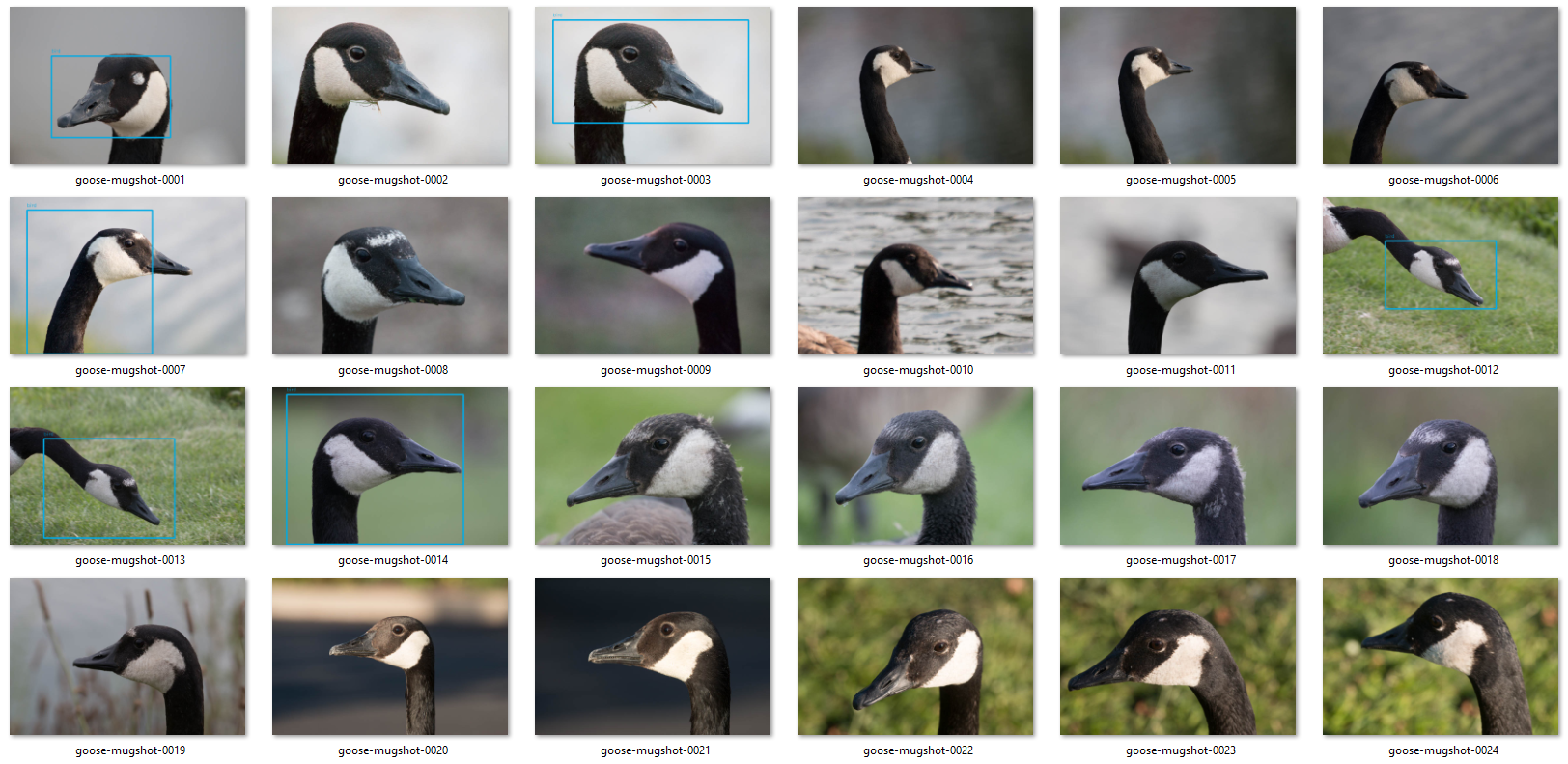
I’ve always wanted to try some computer vision algorithms on Canada geese because they are my favorite animal. For example, counting geese in one image. However, from the experience with the Raccoon Dataset, I realized that the amount of accessible data and computation power would be a bottleneck for me, so I thought I should start with something simpler. For example, locating only the goose’s head, which has a strikingly high-contrast pattern, rather than the goose’s entire body. As a result, I put together 1,000 goose mugshots from my photo collection, labeled the head location with an open-source labeling tool, labelImg, and made a Goose Dataset to experiment on.
First, I used the pretrained tiny-yolo-voc model to detect the geese in my dataset. Geese, like raccoons, aren’t one of the 20 pretrained classes. The model is able to recognize some of the geese as birds. Interestingly, the bounding boxes are usually put around only the heads, not the entire visible body. It could be because that most birds do not have long necks like geese do.
Next, I fine-tuned the model using the goose dataset. In addition to adapting the neural network to 1-class, I also recomputed the ideal sizes of anchor boxes by applying the K-means algorithm on the bounding boxes of the dataset and picking the results from k=5. I separated the 1,000 images into a training set of 800 images and a testing set of 200.
The model is able to recognize a lot of geese after training for just a few epochs. The center points of the bounding boxes are already pretty accurate, but the bounding boxes have much to improve. This is because YOLO’s cost function penalizes on inaccurate center points more than inaccurate bounding boxes, so the center point accuracy is optimized first. Note that some goose heads are marked with two bounding boxes. This is due to the nature of YOLO. Each detection grid would output one bounding box. Among bounding boxes with a certain amount of overlapping (measured by Intersection-Over-Union, IOU), only one would be selected as the final bounding box. In images with two bounding boxes, the two boxes are of significantly different sizes albeit sharing the same center points. As a result, the IOU is not high enough for them to eliminate the other.

After training for 500 epochs, the quality of the bounding boxes improved a lot. Both the center points and the bounding boxes look good for the ones that were detected. However, some geese are still not recognized.


To get a more quantitative evaluation on the results, I followed the YOLO paper and used the mean average precision (mAP) as the metric. I used this implementation of mAP calculation to analyze my predictions. The mAP is 85.50%. Out of the 200 geese in the testing set, 171 were detected, and there were no false positives. For the 171 detected geese, the predicted bounding boxes are also visually close to the ground truth bounding boxes.

Some future work ideas:
- Compute the IOU of predicted and ground-truth bounding boxes to get a quantitative metric.
- Tune the bounding box confidence threshold to get better prediction results.
- The cost function that YOLO optimizes for does not directly translate to mAP. It will be interesting to investigate the gap.
- Perform data augmentation to generate more training data.
- Adding more markers such as eyes and beaks of the geese. Maybe a face recognition algorithm can be incorporated.
Deployment
I used the szaza/android-yolo-v2 Android YOLOv2 implementation. I exported the trained weights to a protobuf file to use with the YOLOv2 app. I can now use my Android phone’s camera for goose detection!
I do not have immediate access to live geese, so I tried the app with a goose decoy. To make the scene look more similar to the training set, I put the decoy on the lawn. Sadly, the decoy is still too different from real geese, and the model doesn’t recognize it as a goose. It could also indicate some overfitting happening.

Next, I tried it with the Goose Dataset images displayed on a monitor. This time, the app is able to detect a goose head.
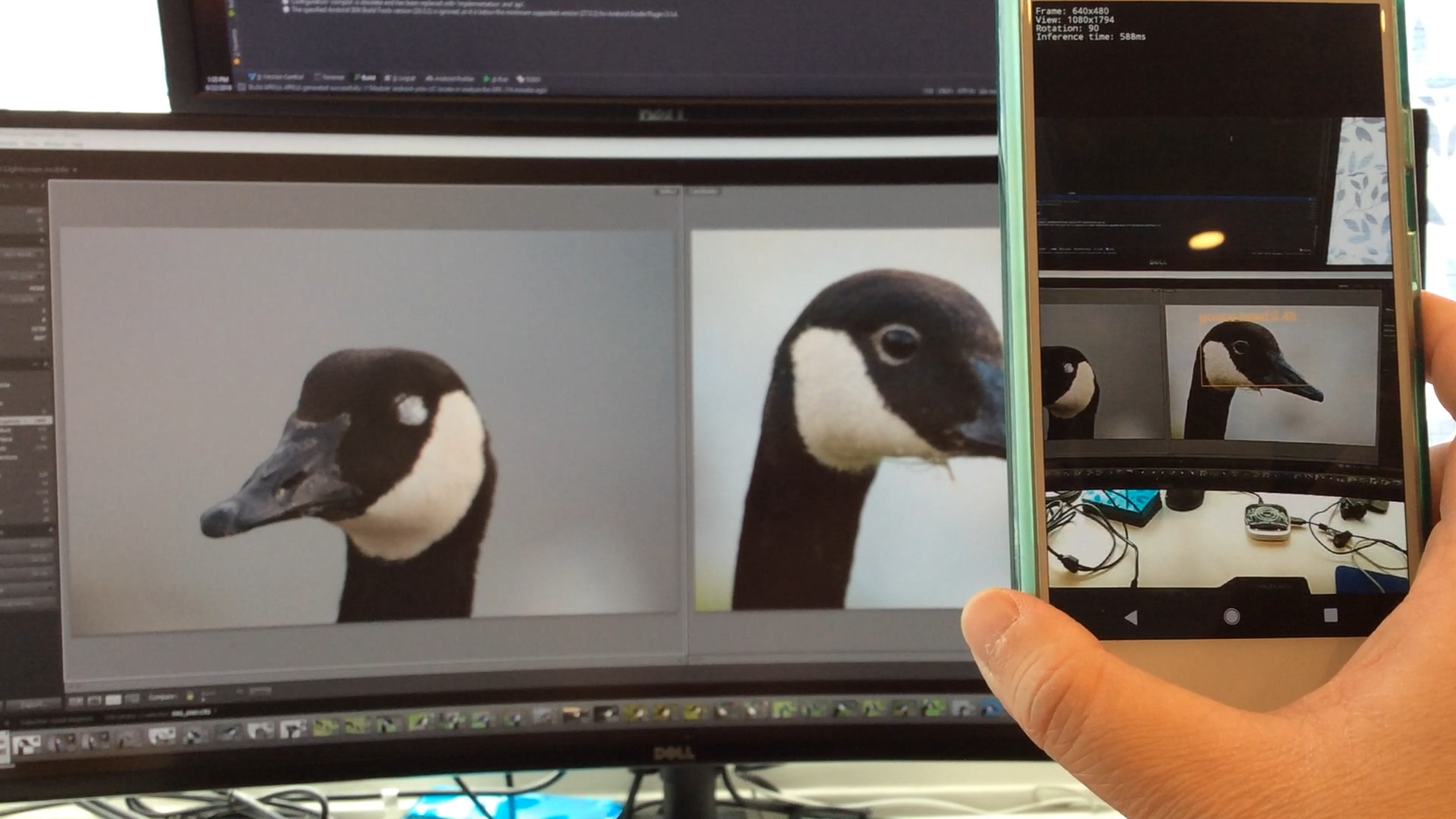
The next step is to further fine-tune the model and try it in the field with live geese.